Generiert von einer Maschine, angestoßen von einem alten Menschen…
Eine Bloggeschichte über Hitze, Verdrängung – und die leise Kraft guter Vorhersagen

Als Martin an diesem Augustmorgen die Rollläden hochzog, war die Stadt schon hell, aber nicht frisch. Die Luft stand in der Straße wie in einem Zimmer, in dem zu lange gekocht worden war. Unten vor dem Bäcker sagte jemand: „Früher war Sommer eben Sommer.“ Martin nickte. Er sagte diesen Satz oft selbst. Nicht, weil er ihn wirklich geprüft hatte, sondern weil er beruhigte. Manche Sätze sind wie Vorhänge: Man zieht sie zu, wenn draußen etwas zu grell wird.
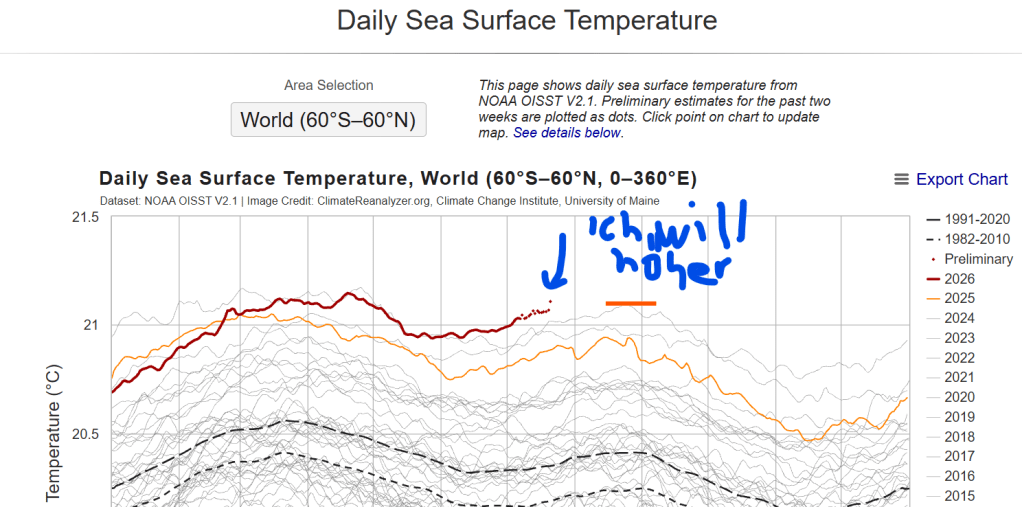
Auf dem Küchentisch lag sein Handy. Eine Nachricht seines Bruders blinkte auf: „Hast du das von Zeke Hausfather gesehen? Die alten Klimamodelle lagen ziemlich gut.“ Martin seufzte. Hausfather – wieder so ein Name aus der Klimadebatte. Doch diesmal blieb er hängen: Die Modelle der 1990er hatten nicht jedes Detail vorhergesehen, aber qualitativ zeigten sie in die richtige Richtung. Sie hatten erkannt, dass steigende Treibhausgase die Erde erwärmen würden. Und doch wirkte es im Jahr 2026 so, als schreite der Klimawandel schneller voran, als viele damals vermutet hatten. James Hansen, einer der frühen und hartnäckigen Warner, deutete genau darauf: Die Klimasensitivität des Planeten könne höher sein als lange angenommen. Zeke Hausfather war mit solchen Schlussfolgerungen vorsichtiger. Für ihn hatten viele alte Modelle bemerkenswert gut gearbeitet, solange man sie an den tatsächlichen Emissionen maß. Aber selbst er schrieb nicht aus bequemer Distanz: Die Intensität des heraufziehenden El Niño und die außergewöhnliche Wärme der Ozeane machten auch ihn sichtbar besorgt.
Martin störte weniger die Dramatik dieser Nachricht als ihre Nüchternheit. Keine apokalyptische Überschrift, kein erhobener Zeigefinger. Nur ein unbequemer Befund: Die Physik hatte nicht übertrieben. Die Modelle hatten nicht „Panik gemacht“. Sie hatten beschrieben, was passiert, wenn wir weiter Kohle, Öl und Gas verbrennen. Und nun saß Martin in seiner Küche, während draußen die Luft flimmerte, und musste sich eingestehen: Vielleicht war das Problem nicht, dass die Wissenschaft zu laut gewesen war. Vielleicht war er zu gut darin geworden, Warnsignale zu überhören.
Am selben Abend fuhr Martin zu seiner Mutter. Sie lebte am Rand der Stadt, in einem Haus mit kleinem Garten. Früher hatte dort im Sommer der Rasen gerochen, jetzt knirschte er unter den Schuhen. Seine Mutter goss die Tomaten mit Wasser aus einer Regentonne, die seit Wochen kaum noch gefüllt worden war. „Man muss sparsamer werden“, sagte sie, ohne Pathos. „Vielleicht sollten wir die Beete anders bepflanzen. Weniger Durstiges. Mehr Schatten.“ Martin merkte, wie anders dieser Satz klang als die großen Appelle im Fernsehen. Nicht: Rette die Welt. Sondern: Sorge dafür, dass dein Garten den nächsten Sommer übersteht.
Am Wochenende traf Martin seinen alten Freund Jens. Jens war kein Klimaleugner, jedenfalls hätte er sich nie so genannt. Er sagte nur: „Das Klima hat sich immer verändert.“ Oder: „Deutschland allein kann doch sowieso nichts machen.“ Oder: „Ich habe gerade andere Sorgen.“ Martin verstand das. Er hatte dieselben Sätze jahrelang benutzt. Sie waren keine Argumente, eher Schutzhelme gegen Überforderung. Doch diesmal antwortete er nicht mit Zahlenkolonnen. Er sagte: „Stell dir vor, dein Arzt hätte dir vor dreißig Jahren gesagt, dass dein Blutdruck langsam steigt. Und jetzt zeigt jede Messung, dass er recht hatte. Würdest du dann sagen: Der Körper hat sich immer verändert?“
Jens schwieg. Nicht überzeugt, aber auch nicht mehr ganz abwehrend. Genau hier beginnt vielleicht Veränderung: nicht in dem Moment, in dem jemand einen Streit gewinnt, sondern in dem ein vertrauter Ausweichsatz für einen Augenblick nicht mehr reicht.
In den nächsten Tagen begann Martin kleine Dinge zu tun, die ihm früher lächerlich gering vorgekommen wären. Er stellte die Heizung im Winterplan ein Grad niedriger ein, bestellte endlich den Stromtarif aus erneuerbaren Quellen, fuhr zwei kurze Wege mit dem Rad statt mit dem Auto und fragte im Haus, ob sich eine gemeinschaftliche Solaranlage lohnen könnte. Nichts davon fühlte sich heldenhaft an. Aber es fühlte sich anders an als Ohnmacht. Es war, als würde er einen Hebel anfassen, von dem er jahrelang behauptet hatte, es gebe ihn nicht.
Er las weiter. Hausfathers Arbeit machte deutlich, dass alte Modelle nicht perfekt waren – kein Modell ist perfekt –, aber dass sie den Zusammenhang zwischen Treibhausgasen und Erwärmung bemerkenswert zuverlässig erfasst hatten. Wenn die Prognosen danebenlagen, dann oft deshalb, weil Menschen anders emittierten als angenommen, nicht weil die Physik falsch war. Das traf Martin. Denn plötzlich verschob sich die Frage. Es ging nicht mehr darum, ob „die Wissenschaft“ übertreibt. Es ging darum, welchen Emissionspfad wir wählen.
Und je länger Martin darüber nachdachte, desto klarer wurde ihm: Diese zusätzliche Energie verschwindet nicht einfach. Sie bleibt im System, wird vom Ozean aufgenommen, wieder abgegeben und wirkt wie ein riesiger, träger Heizkörper, der die Erde nicht plötzlich, aber beharrlich wärmer macht.
Martin stellte sich den Pazifik plötzlich nicht mehr als blaue Fläche auf der Weltkarte vor, sondern als riesigen Atemzug der Erde. Wenn sich das Wasser im zentralen und östlichen tropischen Pazifik ungewöhnlich erwärmt, verschieben sich Regen, Winde und Stürme – nicht überall gleich, nicht immer exakt wie im Lehrbuch, aber doch oft genug, dass Meteorologen die Muster wiedererkennen. El Niño ist kein einzelnes Unglück. Er ist eher eine leise Verschiebung im Maschinenraum des Wetters, deren Geräusch erst an weit entfernten Orten hörbar wird.
In Australien würde man es zuerst vielleicht am Geruch merken: trockene Erde, heißer Staub, Eukalyptus in der Luft. Dort kann El Niño die Wahrscheinlichkeit für trockenere und heißere Phasen erhöhen. Die Weiden werden spröder, Viehhalter rechnen früher, Feuerwehren hören genauer in den Wind. Was man besser machen kann, klingt unspektakulär: weniger Wasser verschwenden, Landschaften feuerfester pflegen, Häuser verschatten, alte Bäume schützen, damit Dörfer nicht schutzlos in der Hitze stehen.
Über Indonesien und Teilen Südostasiens kann sich zur selben Zeit der Himmel verschließen. Wo sonst feuchte Luft aufsteigt, bleibt Regen aus; Reisfelder warten, Torfböden trocknen, Rauch von Bränden legt sich über Städte und Dörfer. Für Menschen, die weit weg leben, wird daraus vielleicht nur eine Schlagzeile über Palmöl, Reispreise oder Lieferketten. Für die Menschen dort ist es die Frage, ob der Brunnen reicht. Besser machen heißt hier auch: weniger Produkte kaufen, die Entwaldung antreiben, Lieferketten hinterfragen, Wälder als Wasserspeicher ernst nehmen.
In Indien und Südasien wird jeder Monsun zur stillen Verabredung zwischen Himmel und Erde. Wenn diese Verabredung wackelt, geraten Ernten, Stromversorgung und Trinkwasser unter Druck. Es muss nicht überall zur Katastrophe kommen, aber schon ein unzuverlässiger Regen reicht, um Familien, Märkte und Regierungen in Sorge zu versetzen. Die Antwort darauf beginnt nicht erst bei internationalen Konferenzen: Städte können Regenwasser speichern, Felder bodenschonender bewirtschaftet werden, Ernährungssysteme robuster und weniger verschwenderisch werden.
In Ostafrika kann El Niño dagegen eine andere Spur ziehen: nicht zu wenig Wasser, sondern zu viel auf einmal. Aus trockenen Flussbetten werden reißende Bahnen, Wege verschwinden, Häuser stehen im Schlamm. Manchmal liegen Dürre und Flut in derselben Lebensgeschichte nur wenige Monate auseinander. Handlungsdruck entsteht hier nicht aus Panik, sondern aus Verantwortung: Frühwarnsysteme ausbauen, Hilfsorganisationen unterstützen, Kommunen klimaresilient planen und begreifen, dass Anpassung kein Luxus ist, sondern Schutz der Schwächsten.
An der Westküste Südamerikas, in Peru und Ecuador, rückt das warme Wasser besonders nah an die Küste. Fischer merken es, bevor es viele andere tun: Strömungen verändern sich, Nährstoffe bleiben aus, Fische wandern oder verschwinden. Gleichzeitig können kräftige Regenfälle Hänge lösen und Straßen unterbrechen. Was weit entfernt wie Naturkunde klingt, wird plötzlich Alltag: Nahrung, Einkommen, Sicherheit. Besser machen heißt auch, Meere nicht zusätzlich zu überlasten, Küsten zu schützen und nicht so zu leben, als seien Ökosysteme unerschöpfliche Lagerhallen.
In Nordamerika kann El Niño im Winter den Jetstream verschieben. Kalifornien kennt dann beides: die Erleichterung über Regen nach trockenen Jahren und die Angst vor zu viel Wasser auf einmal. Weiter im Norden und Westen bleiben manche Regionen milder, andere trockener, Wälder anfälliger. Kein einzelner Sturm beweist den Klimawandel, dachte Martin, aber die Häufung der Extreme stellt eine andere Frage: Warum bauen wir weiter so, als sei das alte Wetter verlässlich? Häuser, Straßen, Stromnetze und Versicherungen müssen auf die Welt vorbereitet werden, die kommt – nicht auf die, an die wir uns erinnern.
Und Europa? Europa liegt nicht im Zentrum von El Niño, aber es lebt nicht außerhalb der Welt. Manche Folgen kommen über Atmosphäre und Ozeane, andere über Preise, Ernten, Fluchtbewegungen, Energiebedarf und politische Spannungen. Ein heißerer Sommer in Südeuropa, trockene Böden, Waldbrandgefahr, teureres Olivenöl, belastete Stromnetze – all das sind keine fernen Fußnoten. Es sind Erinnerungen daran, dass Klimaschutz nicht erst dort beginnt, wo Palmen stehen. Er beginnt im Heizungskeller, im Wahlprogramm, im Speiseplan, im Bahnanschluss, in der Frage, ob eine Stadt Schatten spendet oder Hitze speichert.
Martin las diese regionalen Spuren nicht mehr wie eine Liste von Katastrophen. Er las sie wie Briefe aus verschiedenen Zimmern desselben Hauses. In einem Zimmer brannte es, in einem anderen tropfte Wasser durch die Decke, im dritten wurde die Luft knapp. Man konnte natürlich sagen: Mein Zimmer ist gerade noch bewohnbar. Aber irgendwann begreift man, dass das Haus nur als Ganzes sicher ist.
Martin merkte, dass ihn nicht mehr nur die Bilder aus fernen Ländern beunruhigten. Es war die Zeitachse. Früher hatte er Klimawandel, als etwas betrachtet, das am Rand des Lebens stand: wichtig, aber später; ernst, aber nicht heute. Nun begriff er, dass El Niño diese bequeme Ordnung durcheinanderbringt. Er verschiebt keine abstrakte Linie in einem Diagramm, sondern Jahreszeiten, Ernten, Preise, Wasserstände, Strombedarf und die Belastbarkeit von Menschen.
Es beginnt oft unscheinbar. Ein Sommer wird trockener, ein Winter ungewöhnlich mild, ein Regen bleibt aus oder kommt zu heftig. Dann werden Vorräte knapper, Versicherungen teurer, Pflegeheime heißer, Wälder verletzlicher. Niemand wacht morgens auf und sagt: Heute beginnt die Klimakrise. Sie kommt eher wie ein Wasserfleck an der Decke: zuerst klein genug, um ihn zu ignorieren, dann groß genug, dass man den Eimer holt, und irgendwann so groß, dass man fragen muss, warum niemand früher das Dach repariert hat.
Genau deshalb ist Vorbereitung kein Zeichen von Angst. Sie ist Vernunft. Städte können kühle Räume öffnen, Trinkbrunnen schaffen, Bäume schützen und Asphaltflächen entsiegeln. Familien können Hitzeschutz planen, Nachbarn im Blick behalten, Energie sparen, Regenwasser sammeln und sich fragen, welche Wege wirklich mit dem Auto nötig sind. Unternehmen können Lieferketten prüfen, Gebäude dämmen, Solardächer nutzen und nicht länger so tun, als sei billige Energie aus fossilen Quellen ein Naturgesetz.
Martin dachte an seinen Freund Jens. Vielleicht würde Jens noch immer sagen, man könne ohnehin nichts ändern. Aber das stimmte nicht. Man konnte nicht allein den Pazifik abkühlen. Man konnte nicht allein die Atmosphäre zurückdrehen. Aber man konnte aufhören, das Falsche zu normalisieren. Man konnte wählen, kaufen, bauen, heizen, fahren, essen und reden, als hätte die Zukunft ein Mitspracherecht.
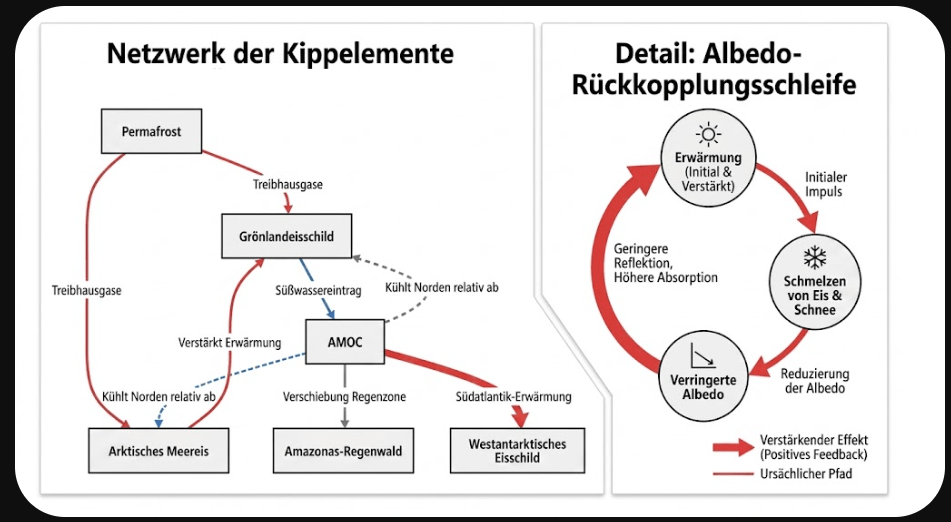
Am Ende war es nicht El Niño, der Martin am meisten erschreckte. El Niño ist ein natürlicher Takt im Klimasystem, ein wiederkehrendes Schwingen von Ozean und Atmosphäre. Das eigentliche Problem ist, dass dieses Schwingen heute auf einer wärmeren Erde stattfindet. Wir haben die Grundtemperatur angehoben. Dadurch bekommt jedes Extrem mehr Spielraum: Hitze startet von einem höheren Niveau, Dürren trocknen schneller aus, Starkregen fällt in eine wärmere Luft, die mehr Wasserdampf halten kann.
Das ist der Satz, dem man nicht länger ausweichen sollte: Wir verbrennen in kurzer Zeit Kohle, Öl und Gas, die über Millionen Jahre entstanden sind, und wundern uns dann, dass die Atmosphäre reagiert. Die Klimaforschung hat diesen Zusammenhang nicht erst gestern erkannt. Sie hat ihn gemessen, modelliert, überprüft und immer wieder bestätigt. Wenn gut geprüfte Vorhersagen eintreffen, ist das kein Grund, die Schultern zu zucken. Es ist der Moment, in dem Verantwortung beginnt.
Martin stellte sich vor, wie er beim nächsten Gespräch nicht mehr mit Schuld begann, sondern mit einer Frage: Was wäre, wenn wir das schaffen könnten, ohne unser Leben ärmer zu machen? Wärmere Häuser mit weniger Energieverlust. Städte mit Schatten statt Betonhitze. Busse und Bahnen, die funktionieren. Dächer, die Strom erzeugen. Felder, die Wasser halten. Mahlzeiten, die weniger verschwenden. Politik, die nicht nur Krisen verwaltet, sondern Risiken senkt. Klimaschutz ist dann kein Verzicht auf Zukunft, sondern die Entscheidung, sie nicht weiter zu verspielen.
Er wusste, dass nicht jeder sofort seine Meinung ändern würde. Verdrängung verschwindet selten durch einen einzigen Text. Aber vielleicht blieb ein Satz hängen: Die Warnungen waren nicht zu schrill, sie waren oft erstaunlich genau. Und wenn das stimmt, dann ist Nichtstun keine Neutralität mehr. Es ist eine Entscheidung, die andere bezahlen. Ruhig betrachtet, klar ausgesprochen, bleibt deshalb nur eines: Wir müssen die Emissionen schneller senken und uns zugleich besser schützen. Nicht irgendwann. Jetzt, solange aus Handlung noch Vorsorge werden kann.
Zeke Hausfathers Artikel zum aufziehenden El Niño 2026/27:
https://www.theclimatebrink.com/p/the-strongest-el-nino-ever